

Every reporting cycle, your team does the same thing: open EDGAR, run a search, wade through filing after filing, manually extract disclosure language, and then spend two days building a benchmark table you'll reuse once. It works. It also takes a week that your team doesn't have.
AI has changed what's possible here not by replacing the research, but by collapsing the time it takes to do it well. This guide covers exactly how CFO teams and SEC reporting professionals can use AI to research EDGAR filings faster, what the practical limitations are, and where purpose-built EDGAR research tools fit into the workflow.
By the end, you'll know which EDGAR research tasks AI handles reliably, how to structure searches that actually surface relevant peer language, and what a modern AI-assisted filing workflow looks like in practice.
What Is EDGAR and Why Does Manual Research Take So Long?
EDGAR (Electronic Data Gathering, Analysis, and Retrieval) is the SEC's public database containing every filing by U.S. public companies since the early 1990s. Manual research is slow because EDGAR's native search returns unranked results with no relevance scoring, no section-level filtering, and no cross-filing synthesis. A typical peer benchmarking exercise covering 8 to 10 companies across five disclosure sections takes two to four days of analyst time.
EDGAR the Electronic Data Gathering, Analysis, and Retrieval system is the SEC's public database of all company filings. Every 10-K, 10-Q, 8-K, DEF 14A, and comment letter exchange filed by a U.S. public company since the early 1990s lives in EDGAR. According to the SEC's 2024 Annual Report, EDGAR processes over 500,000 filings annually from approximately 8,000 active reporting companies.
The problem is retrieval. EDGAR's native search interface EDGAR Full-Text Search is powerful but unranked. A search for "cybersecurity disclosure" in 10-K filings returns thousands of results in reverse chronological order with no relevance scoring. Finding the five peer disclosures most similar to yours in industry, market cap, and risk profile requires opening dozens of filings individually, scanning MD&A (Management Discussion and Analysis) sections manually, and copying language into a document.
For a typical 10-K benchmarking exercise covering 8–10 peer companies across five disclosure sections, this process takes 2–4 days of analyst time. It's not complex work. It's slow work and slow work during a close cycle is a real cost.
As SEC Chief Accountant Paul Munter has noted, the quality of financial reporting depends on the quality of the research and analysis that supports it. This is the retrieval bottleneck that AI addresses.
What Can AI Actually Do for EDGAR Research?
AI accelerates EDGAR research in three ways: retrieval acceleration through semantic search that ranks filings by relevance instead of date, extraction within filings that locates specific sections without manual scrolling, and pattern detection across filings that identifies disclosure trends among 50 or more peers simultaneously. AI cannot make legal judgments about disclosures or replace technical accounting review.
AI tools speed up EDGAR research in three specific ways: they retrieve relevant filings faster, they extract target language from within filings without manual scanning, and they surface patterns across large numbers of filings simultaneously.
Retrieval acceleration AI can process a natural-language query ("How are SaaS companies with $1B–$5B revenue disclosing AI model risk in their 10-K risk factors?") and return a ranked, filtered set of relevant filings instead of an unranked dump. Platforms like Finrep query EDGAR natively and apply this kind of semantic filtering by industry, filing type, date range, and company profile.
Extraction within filings Once you have the right filing, AI can locate and extract a specific section (the exact climate risk disclosure in Item 1A, or the revenue recognition policy in Note 2) without requiring you to scroll through a 120-page PDF. This alone eliminates the majority of manual time in most benchmarking workflows.
Pattern detection across filings AI can process 50 filings simultaneously and identify how a specific disclosure topic is being handled across peers what language is common, what's shifting year-over-year, and where your own disclosure may be an outlier. This is what used to require a team of analysts and a week of spreadsheet work.
What AI cannot do: make legal judgments about your specific disclosure, certify that peer language is appropriate for your situation, or replace the technical accounting review that must precede any filing submission. A Deloitte 2024 CFO survey found that 72% of finance teams using AI tools reported faster research cycles but emphasized that human judgment remained essential for disclosure decisions. The outputs are research inputs reviewed and approved by your team before anything goes into a draft.
How Does EDGAR Full-Text Search Work, and Where Does It Fall Short?
EDGAR Full-Text Search indexes complete filing text from 1996 onward and supports Boolean queries, phrase matching, and filtering by form type, date range, and entity. Its four major limitations for research workflows are: no relevance ranking, no semantic understanding of disclosure concepts, no cross-filing synthesis or pattern detection, and no section-level filtering within individual filings.
EDGAR Full-Text Search indexes the complete text of filings submitted after 1996 and allows Boolean and phrase-based queries. It supports filtering by form type, date range, and filing entity and it's free.
The gaps are significant for research workflows. As former SEC Commissioner Hester Peirce has acknowledged, EDGAR's search infrastructure has not kept pace with the volume and complexity of modern filing data:
No relevance ranking. Results appear in reverse chronological order. A highly relevant 10-K from a direct peer filed two years ago appears below an irrelevant filing from last week.
No semantic understanding. Searching for "going concern disclosure" returns filings containing those exact words. It won't surface filings that discuss the same concept using different terminology "substantial doubt about the entity's ability to continue as a going concern" (the ASC 205-40 language) versus informal paraphrases.
No cross-filing synthesis. EDGAR returns individual filings, not aggregated patterns. Understanding how 30 peers handled a disclosure topic requires opening 30 filings.
No section-level filtering. A search returns the full filing. Finding the MD&A or a specific footnote within that filing is manual.
AI-powered EDGAR tools address all four gaps. They layer semantic search, relevance ranking, section extraction, and cross-filing pattern analysis on top of EDGAR's underlying index giving you the breadth of EDGAR's database with a fraction of the retrieval friction. According to Gartner's 2024 research on AI in finance, 58% of finance organizations are either piloting or scaling AI for research and analysis workflows.
What Are the Most Time-Consuming EDGAR Research Tasks for CFO Teams?
The four most time-consuming EDGAR research tasks for CFO teams are peer disclosure benchmarking (two to four days per topic area), SEC comment letter research, roll-forward updates comparing prior-year to current-year disclosure language, and new topic research when emerging disclosure requirements demand rapid understanding of early-adopter peer practice.
The research tasks that consume the most analyst time in a typical SEC reporting cycle fall into four categories.
Peer disclosure benchmarking is the highest-time task. Before finalizing language in a 10-K's risk factors, MD&A, or critical accounting estimates, most CFO teams want to know how comparable peers have handled the same topic. Building that benchmark manually finding the right peers, locating the right sections, extracting language, normalizing for comparison takes 2–4 days per topic area.
SEC comment letter research is the second major time sink. The SEC's Division of Corporation Finance issues thousands of comment letters annually. When your team receives a comment letter, the most effective first step is finding how peers have responded to similar comments in the past. Those exchanges are public they live in EDGAR but finding the right ones requires knowing that comment letter correspondence appears under form type "UPLOAD" and searching by the relevant company and topic. Many teams don't know this and miss the research entirely.
Roll-forward updates updating prior-year disclosure language for a new filing period require comparing your current draft against your prior filing, identifying what's changed, and verifying that peers are handling similar changes consistently. Without AI, this is a manual side-by-side review.
New topic research when a new disclosure requirement emerges (climate risk, AI-related risk, cybersecurity incident reporting) teams need to quickly understand how early-adopting peers are handling it before the company's own deadline. EDGAR contains this information, but retrieving it fast requires either a lot of analyst time or a tool built to surface it.
AI-powered EDGAR research tools address all four of these time-intensive tasks. Teams using EDGAR-native AI platforms reduce research time on these tasks from days to hours, with outputs citation-linked back to the source filings so every benchmark point is audit-ready.
How to Use EDGAR Full-Text Search Effectively (Without AI)
Effective manual EDGAR research relies on four techniques: using exact ASC phrase searches for regulatory language, filtering by SIC code rather than industry description for precise peer sets, searching form types UPLOAD and CORRESP to find SEC comment letter correspondence directly, and applying strategic date ranges with 18-month windows for current practice and multi-year ranges for trend analysis.
Before reaching for an AI tool, it helps to understand what EDGAR's native capabilities can do because for targeted, specific queries, EDGAR Full-Text Search is often sufficient.
The most useful techniques for reporting professionals:
Use exact phrase searches for regulatory language. Searching for the exact ASC (Accounting Standards Codification) phrase e.g., `"reasonably possible that a material loss"` surfaces filings using that specific contingency disclosure language. This is more precise than keyword searches and returns tighter results.
Filter by SIC code, not just industry description. EDGAR's SIC (Standard Industrial Classification) code filter is more precise than its industry text search. If you're benchmarking enterprise software peers, filtering to SIC 7372 (Prepackaged Software) produces a cleaner comparable set than searching "software" in the company name field.
Search comment letter correspondence directly. Form type "UPLOAD" in EDGAR contains SEC staff comment letters. Form type "CORRESP" contains company responses. Searching these form types with a relevant topic term e.g., `"segment reporting"` in CORRESP filings from the past 24 months surfaces how companies are actively responding to SEC scrutiny on that topic right now. Deloitte's 2025 roadmap to SEC comment letter considerations identifies MD&A, segment reporting, and EPS as the three most common comment areas these are the highest-value topics to research first.
Use date ranges strategically. For benchmarking purposes, filings from the past 18 months are most relevant they reflect current enforcement climate and recent standard updates. For understanding how a disclosure topic has evolved, running the same search across 2022–2024 versus 2025–2026 reveals trend direction.
These techniques get you further than most teams realize. The AICPA's Center for Audit Quality has noted that structured benchmarking against peer filings is one of the most effective ways to improve disclosure quality. The limitation hits when you need volume when you need to benchmark 15 peers across five disclosure topics simultaneously, or when you need to find 10 comment letter response examples fast, not one.
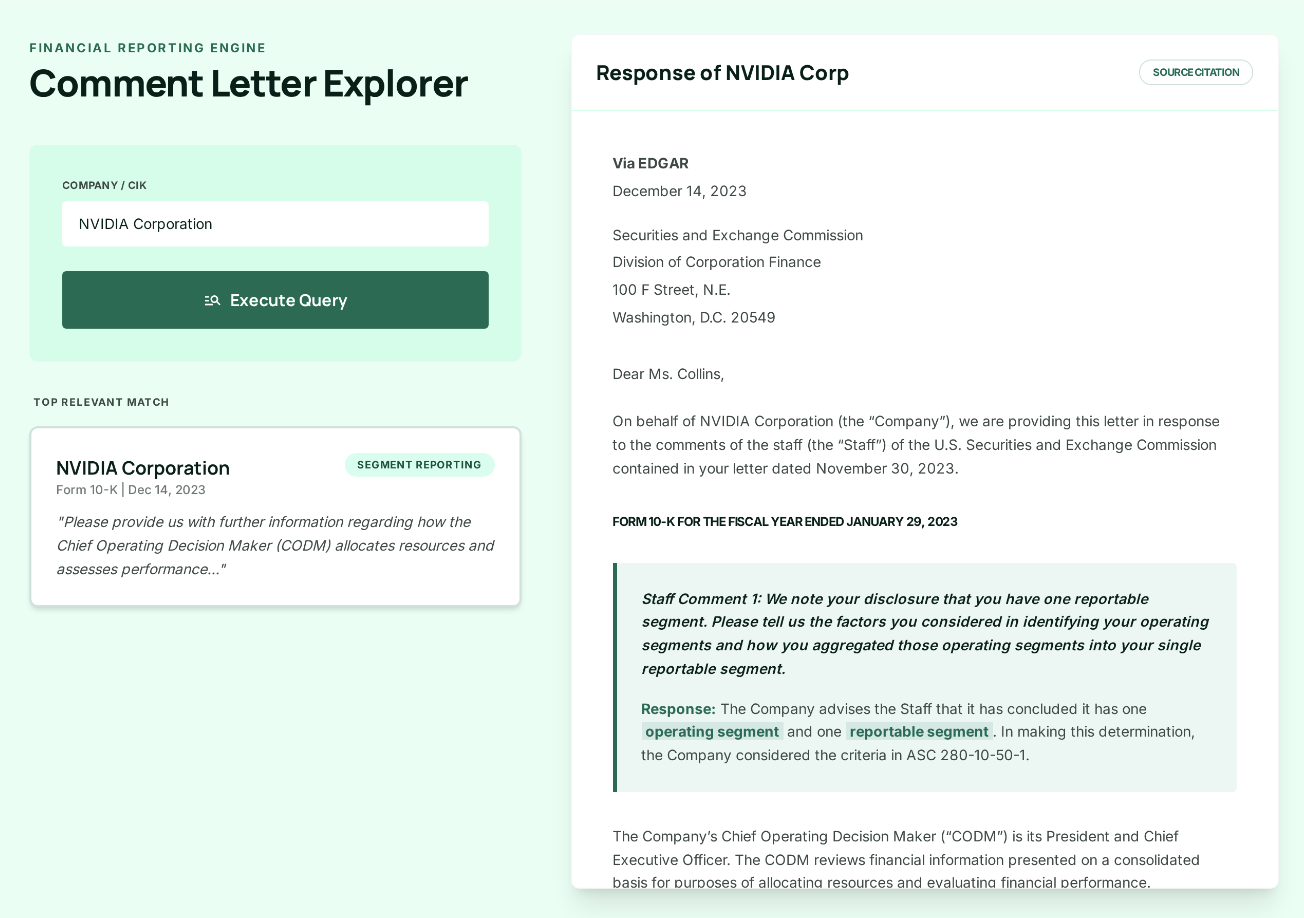
Finrep.ai queries EDGAR natively using natural language, applies semantic ranking to surface the most relevant peer filings, extracts specific disclosure sections, and generates cited benchmark language linked back to source filings. A peer benchmarking task that takes two to three hours manually completes in under 30 minutes, with every output linked to its EDGAR source for audit verification.
Finrep.ai is an AI-powered financial disclosure intelligence platform built specifically for SEC reporting and the Office of the CFO. Its core capability: query EDGAR natively using natural language or structured search parameters, surface relevant peer filings with semantic ranking, extract specific sections, and generate cited disclosure language all with every output linked back to its source filing.
The workflow difference in practice:
Without Finrep.ai: A reporting manager spends 90 minutes identifying 10 peer companies, locates their most recent 10-K filings in EDGAR, opens each filing, manually navigates to the climate risk disclosure in Item 1A, copies relevant language into a Word document, and formats a comparison table. Total time: 2–3 hours per topic, per filing cycle.
With Finrep.ai: Fina, Finrep's AI, runs the peer identification and section extraction simultaneously across all 10 companies. The reporting manager reviews a structured comparison of peer disclosure language each item cited to its source filing in under 30 minutes. The output is audit-ready: every benchmark point links directly to the EDGAR source.
The distinction that matters for a reporting team: Finrep.ai doesn't generate new disclosure language from scratch. It surfaces what public peers have filed language that has already been submitted to and reviewed by the SEC. That's a fundamentally different risk profile from using a general-purpose AI tool to draft disclosures from memory.
Finrep.ai is SOC 2 Type II and ISO 27001 certified. Client data is never retained or used to train models (zero data residency). Clients include FOX, Roku, HP, RingCentral, Infosys, and Sixt.
Finrep.ai is available for teams looking to implement this workflow. Request access to Finrep to evaluate it against your current EDGAR research process.
What EDGAR Research Tasks Should AI Handle and Which Shouldn't It?
AI is well-suited for peer benchmarking, comment letter pattern research, roll-forward comparison, new disclosure topic scans, and section extraction from filings. Tasks that must remain human-driven include determining whether a peer's disclosure approach fits your company's specific circumstances, assessing materiality, making accounting policy elections, certifying ASC standard compliance, and crafting SEC comment letter responses.
Not every EDGAR research task is equally suited to AI. Understanding the distinction prevents both underuse and overuse.
Strong AI use cases in EDGAR research:
- Peer benchmarking: finding comparable companies and extracting their disclosures on a specific topic
- Comment letter pattern research: identifying how peers have responded to SEC comments on a particular accounting area
- Roll-forward comparison: identifying what changed between your prior and current filing
- New disclosure topic scans: quickly surveying how early filers are handling a newly required or newly common disclosure area
- Section extraction: pulling a specific note or MD&A section from a target filing without reading the whole document
Tasks that still require human judgment:
- Determining whether a peer's disclosure approach is appropriate for your company's specific facts and circumstances
- Assessing materiality of a disclosure item
- Making accounting policy elections
- Certifying that disclosure language satisfies the relevant ASC standard the FASB Accounting Standards Codification (free access; license agreement required on first visit) remains the authoritative source, not peer comparisons
- Responding to SEC comment letters AI can surface relevant peer responses; your legal and accounting team must craft and certify your own
The right frame: AI handles the retrieval and synthesis layer. Your team handles the judgment layer. As SEC Chair Gary Gensler noted in 2023 remarks, technology can "increase efficiency and lower costs in capital markets" but accountability for disclosure accuracy remains with the certifying officers. The goal is to shift analyst time from low-judgment manual work (finding and copying filings) to high-judgment expert work (evaluating and deciding).
How to Build an AI-Assisted EDGAR Research Workflow for Your Team
An effective AI-assisted EDGAR workflow follows five steps: define the peer benchmark set of 8 to 12 comparable companies by SIC code, market cap, and revenue; identify the specific disclosure sections to benchmark; run the extraction using an AI tool or EDGAR manually; review and annotate the benchmark output with expert judgment; and draft disclosure language against the benchmark rather than from scratch.
The teams that get the most out of AI-assisted EDGAR research treat it as a structured workflow change, not a one-off speed-up. A McKinsey 2024 report on AI in finance found that organizations implementing structured AI workflows in financial reporting realized 30-40% time savings compared to ad hoc adoption. Here's what that looks like in practice.
Step 1: Define the benchmark set before you search. Start each research project by defining your peer universe 8–12 companies comparable in industry, size, and business model. SIC code, market cap band, and revenue range are the key filters. This takes 15 minutes but prevents an hour of irrelevant results. Finrep.ai's peer selection tool automates this against EDGAR's company database.
Step 2: Identify the specific disclosure sections relevant to your topic. For a climate risk disclosure review, that's Item 1A (Risk Factors) and potentially the MD&A. For revenue recognition, it's the revenue recognition accounting policy note. Being specific about which section you're benchmarking produces usable outputs; asking for "everything about climate" in a 10-K produces noise.
Step 3: Run the extraction. With Finrep.ai, this means prompting Fina with the peer set and target section. Without a purpose-built tool, this means opening each filing in EDGAR and manually navigating to the relevant section the limitation EDGAR Full-Text Search imposes.
Step 4: Review and annotate the benchmark output. The extraction gives you comparable language. Your job is to identify what's most relevant to your situation, flag any outliers, and note where your current disclosure differs from emerging peer practice. This review step cannot be automated it requires your team's judgment.
Step 5: Draft against the benchmark, not from scratch. Use the benchmark language as a reference set for your own disclosure drafting. This reduces first-draft time and grounds your language in documented peer practice which is both a quality signal and a defensible position if the SEC asks about your disclosure choices.

For context on how this compares to traditional EDGAR research workflows, see how top financial reporting teams are switching from Intelligize to Finrep for EDGAR research and benchmarking.
Is AI-Assisted EDGAR Research Audit-Ready?
AI-assisted EDGAR research is audit-ready when every output links to its source filing with company name, filing date, form type, and section. The SEC has not restricted AI use in the research and drafting process; the accountability requirement is that officers certify the accuracy of the final filing. General-purpose AI tools that generate language from training data without source citations are not audit-ready.
Yes when the AI tool links every output to its EDGAR source. This is the critical distinction between general-purpose AI tools and purpose-built financial disclosure platforms. As PCAOB Chair Erica Williams has emphasized, audit evidence must be traceable to its source, and the same principle applies to the research that informs disclosure drafting.
A general-purpose AI tool generating disclosure language from training data cannot tell you where that language came from. Your auditor cannot verify it against a source document. That's not audit-ready it's a liability.
An EDGAR-native tool like Finrep.ai generates outputs where every benchmark point, every extracted section, and every comparable disclosure is linked back to the specific EDGAR filing it came from company name, filing date, form type, section. Your auditor can click through and verify independently. That's audit-ready.
The SEC's Division of Corporation Finance has not issued specific guidance restricting AI use in the research and drafting process. The accountability requirement is unchanged: the company's officers certify the accuracy and completeness of every filing. AI that improves the research quality behind that certification is consistent with that requirement. AI that replaces the human certification is not.
Companies including ON Semiconductor and Hewlett Packard Enterprise have publicly disclosed using AI tools in their financial reporting workflows. The practice is mainstream. The differentiator is whether the AI tool produces verifiable, sourced outputs or black-box suggestions.
Frequently Asked Questions: AI and EDGAR Filing Research
What is EDGAR and how do reporting teams use it?
EDGAR (Electronic Data Gathering, Analysis, and Retrieval) is the SEC's public database of all company filings 10-Ks, 10-Qs, 8-Ks, comment letter exchanges, and more. Reporting teams use it to research peer disclosure language, find SEC comment letter precedents, benchmark accounting policy language, and verify what competitors have disclosed publicly. Access is free at edgar.sec.gov.
How does AI speed up EDGAR research compared to manual methods?
Manual EDGAR research requires opening individual filings, navigating to target sections, and copying language into a comparison document typically 2–4 days of analyst time per benchmarking topic. AI tools layer semantic search, relevance ranking, and section extraction on top of EDGAR's index, collapsing the same research into 30–60 minutes. Finrep.ai's EDGAR-native AI returns citation-linked benchmark outputs, reducing 10-K research cycles from 10 days to 3–4 days (Finrep client data, 2025).
Can I use a general-purpose AI tool like ChatGPT to research EDGAR filings?
You can use general-purpose AI tools to interpret or summarize EDGAR filings you've already retrieved but they cannot search EDGAR directly, and their outputs won't be citation-linked to source filings. For audit-ready research, you need either EDGAR's native search interface or a purpose-built tool that queries EDGAR and links every output back to its source document.
What types of EDGAR filings are most useful for disclosure benchmarking?
10-K annual reports are the primary benchmarking source for most disclosure topics they contain the full risk factors, MD&A, and footnotes. 10-Q quarterly reports are useful for monitoring how peers handle rapidly evolving disclosures mid-year. Comment letter correspondence (form types UPLOAD and CORRESP in EDGAR) shows how peers have responded to SEC scrutiny on specific accounting topics often the most practically useful research source for teams facing a comment letter of their own.
How does Finrep differ from using EDGAR Full-Text Search directly?
EDGAR Full-Text Search returns unranked results in reverse chronological order with no semantic filtering, no section-level extraction, and no cross-filing synthesis. Finrep layers semantic ranking, peer filtering by company profile, section-level extraction, and pattern analysis across multiple filings simultaneously with every output linked to its EDGAR source. A search that takes 3 hours in EDGAR takes 20–30 minutes in Finrep.
Is AI-generated content in SEC filings legally acceptable?
Yes AI-assisted research and drafting is consistent with SEC requirements when the final submission is reviewed and certified by the company's officers. The SEC requires human accountability for all disclosures. AI outputs must be verifiable and sourced: every language benchmark should trace back to a named EDGAR filing. Finrep.ai's outputs are citation-linked by design, making them auditor-verifiable.
Key Takeaways
- EDGAR contains the most complete, authoritative set of peer disclosure data available but native EDGAR search is unranked, unfiltered by relevance, and requires manual section navigation.
- AI speeds up EDGAR research in three ways: faster retrieval of relevant filings, section-level extraction without manual scanning, and cross-filing pattern analysis across large peer sets simultaneously.
- The research tasks with the highest time savings from AI are peer disclosure benchmarking, comment letter precedent research, and roll-forward comparison reviews.
- AI handles the retrieval and synthesis layer. Your team handles the judgment layer materiality assessment, accounting policy decisions, and officer certification cannot be automated.
- Finrep.ai client teams report their 10-K research cycles shrink from 10 days to 3–4 days, with 60–70% fewer auditor review loops (Finrep.ai client data, 2025).
Finrep.ai is an AI-powered financial disclosure intelligence platform for the Office of the CFO SOC 2 Type II and ISO 27001 certified, backed by Accel, with zero data residency. Request access to explore its EDGAR research capabilities.






